

by Kal Kanev
Director, Global AI Practice DXC Technology
Kal also features in our new Executive Data Series, where he discusses the importance of innovating and industrializing AI for enterprise growth. Listen to the conversation.
Artificial intelligence — once considered an exotic preserve of the tech-savvy few — is now a mainstream force multiplier. To treat AI as ephemeral is risky when it is transforming core business applications and processes. In a survey of 600 CIOs and other technology leaders conducted by MIT Technology Review Insights, 6% or less say their companies are not using AI today. Today’s consumers engage daily in AI-enabled transactions to complete routine tasks such as making travel reservations, managing their financial affairs and shopping online.
AI is here to stay, but so too are the issues and business implications around its use and impact. Companies leveraging AI face emerging legal and regulatory demands, as well as continuing distrust — even fear — of AI among consumers. The greater deployment of AI models that augment human decision-making, the greater the need to understand human oversight and ethics of algorithm development.
Companies developing AI need to ensure fundamental principles and processes are in place that lead to responsible AI. This is a requirement to ensure continued growth in compliance with regulations, greater trust in AI among customers and the public, and the integrity of the AI development process. Read on to learn why this is important and examine the values that your company should strive to instill, both in working practices and in the people who perform them.
How did we get here?
To understand the capabilities that organizations need to create and operate AI responsibly, we first need to understand why and how AI came to be viewed with suspicion.
- Disregard for the law. Organizations have in the past used AI in clear violation of the law, or as vehicles to bypass legal restrictions in a manner that violates the spirit — not the letter — of the law. There are also AI applications (such as deepfakes) that have a large number of questionable uses.
- Diversity of values. Certain behavior patterns are considered fair and ethical by one group, while for another group they are not compatible. AI applications can therefore act unethically according to the value set of one stakeholder group, while being perfectly ethical under the value set of the group that designed them. The public perceives this as a technical AI issue and not differentiated from other cases where AI has unethical outcomes, leading to a mistrust in AI itself.
- Lack of robustness. Organizations have developed AI applications that were not sufficiently hardened against possible unintended uses, for example:
- By children or other agents who have no awareness of the limits (and purpose) of an AI
- By users with malicious intent feeding in bad data, or responding to a device instead of a person.
In addition, AI can have bugs or security gaps just like other IT applications that can lead unintentionally to harmful behavior.
- Biased input. Where algorithms learn from training data, several types of bias in the training data can lead to unintended outcomes. For example, algorithms that learn from previous human decisions will also learn and adopt any human behavior bias. Selection bias can lead to different population groups being unevenly represented in the training data.
- Lack of transparency. Even if an algorithm’s outcome appears to be generally fair and unbiased, an inability to explain the results of a specific case will cause distrust, particularly among the stakeholders that were impacted adversely. If the origin of an outcome is unknown, it is also hard to prove that it is not unduly discriminatory against a specific characteristic of an individual.
The solution: Introduce responsible AI
Businesses need AI they can trust. They need to know that AI’s decisions are lawful and align with their values. If AI systems — and the human beings behind them — are not demonstrably worthy of trust, unwanted consequences ensue, resistance increases, growth opportunities are missed and, potentially, reputations are damaged.
Too often, however, making AI responsible is an afterthought for many organizations. At first, they are focused more on identifying high-impact use cases in which to apply AI than with any ethical considerations. Next, they implement AI solutions based on existing company policies, rather than considering whether these are sufficient for purpose or need to be modified. Finally, when the resulting AI provides adverse results, they question AI’s overall function and value, and only then consider the option of “making” the AI ethical after the fact. This leads to new guidelines, legislation, court rulings and other forms of normalization that eventually cycles back to developing brand new models and AI solutions.
Ethics and compliance should not be an afterthought; companies should “do it right” from the start. The ethical and compliant use of AI must become ingrained in an organization’s ML/AI DNA. The best way to do this is to establish, at a minimum, fundamental guiding principles and capabilities for governing AI development.
1. Align to ethical values
Organizations should be very specific in defining and communicating the values, laws and regulations under which they operate, and the behavior patterns (of applications) that they consider to be fair and ethical under a responsible AI framework. At a minimum, such framework should provide clear guidelines for how AI processes meet these standards:
- All AI use must be lawful.
- AI must respect data privacy.
- Risks from AI use to the business should be studied and mitigated.
- The social impact of AI use should be understood.
- AI should clearly present itself as AI and not pretend to be human.
As part of this “culture of responsible use,” all participants should also agree that they will not use AI:
- Beyond what it is proven to do correctly
- For purposes other than agreed
- For purposes that could, objectively, be considered unethical
2. Introduce accountability through an organizational structure
The organizational structure for the governance of AI should be defined and current. Within it, specific roles and responsibilities should be assigned to individuals at all levels of the organization to establish accountability during and after the AI development process (an example is provided in Figure 1).
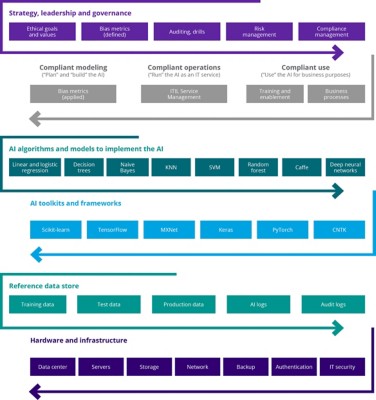
Specific individuals' tasks could include:
- Implementing the responsible AI framework, complying with the organization’s standards. Note: These individuals could also act as advisors and arbitrators in case of doubt or disagreement about the compliance of a specific AI endeavor.
- Identifying and mitigating (taking corrective actions) specific AI-related risks.
- Conducting adequate testing and profiling of the AI, as well as continuous monitoring.
There should also be clear communication to developers, testers, their managers, project / product owners and other stakeholders about the requirements and best practices expected from them.
3. Mitigate risk and increase resilience
Robustness of a technical system in general is its ability to tolerate disruptions. AI systems must be developed in such a way that they behave reliably and as intended, producing accurate results and resisting external threats.
An AI system, like any other IT system, can be compromised by adversarial attacks. For example, hackers targeting the data (“data poisoning”) or the underlying infrastructure (both software and hardware) can cause the AI to make different decisions or responses, or shut down altogether. Exposed details about an AI model’s operation enables attackers to use the AI with specifically-prepared data to generate a specific response or behavior.
Biased or insufficient data may also create AI that is not robust enough for its task. In fact, any bias in the AI can be considered to cause non-robust behavior, since a lack of bias and fairness is a typical design requirement for an AI.
To improve the robustness of your AI, we suggest taking the following measures:
- Anticipate potential attacks. Consider the different types of attacks to which the AI system could be vulnerable (e.g., data pollution, physical infrastructure, cyberattacks) and test the AI thoroughly in various conditions and environments. This will help the AI become resilient to changes in its operating environment and hardened against the various types of attacks anticipated.
- Consider dual-use. Consider to what degree the AI system could be dual-use.
- Assess risks. Measure and assess risks and safety, in particular risk to human physical integrity.
- Analyze security or network problems. Determine whether, for example, cybersecurity hazards could pose safety risks or damage due to unintentional behavior of the AI system.
- Monitor and test. Document and operationalize processes for testing and verifying the reliability of the AI system. Check the system regularly to determine whether the AI is meeting its goals, purposes and intended use.
- Create a fallback plan. Decide the course of action to take if the AI encounters adversarial attacks or other unexpected situations, e.g., switching from a statistical to rule-based procedure, or requesting a human operator to sign-off before continuing to act.
- Document failure. Record instances where an AI system fails in certain types of settings.
4. Detect and remediate bias
For AI to be ethical, stakeholders must be confident that the AI makes decisions that society would consider ethical and fair — and not only what is legal or permitted by a code of conduct. An important aspect of this is that AI decisions and behavior are seen as unbiased, i.e., not unduly favoring or disfavoring certain people over others. Of course, human prejudice can lead to biased/unfair human decisions and AI cannot differentiate between good human judgement and prejudice. Therefore, if trained with biased data (input), AI will learn to repeat the underlying human prejudice and deliver biased/unfair decisions (output) (see Figure 2).
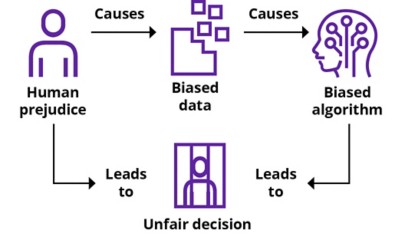
Human prejudice is not the only cause of bias. Bias in AI training data is a common and typical cause for AI behavior that is considered by stakeholders to be unfair. Data can be biased by “unknown unknowns.” So it is important to develop ways to detect bias and establish procedures for mitigating it.
There is no fool-proof method of detecting all bias in your training and test data, but it starts with understanding how a particular data sample was gathered and whether specific types of bias can have crept into that sample. Check your data sampling methods meticulously for known types and causes of bias and re-evaluate this again later as more details are known or uncovered.
Asking the following questions can provide insight into the root cause of the bias, and even suggest a solution:
- Is the data representative of the population the AI will serve? For example, if you develop an AI to serve university students, training and test data should be representative of the student population, not the general population. Care must be taken with historic test and training data, as it may have a historic bias. In the example of the university student population, historic student data may over-represent white and male students, as compared to a contemporary student population.
- Do training and test data cover a representative diversity of cases? For example, you may be tempted to build your training and test data with parts of the population that are easily accessible, but this introduces a “selection bias” if later you want to run your machine on the general population. An extreme case of this is self-selection, i.e., when your training and test data is based on people who volunteer to be included in the training exercise. Self-selection will almost certainly lead to data samples that are not representative.
- Are any predictor variables you excluded from your model truly irrelevant? There may be a relationship that you are not aware of.
- If you select the data sample yourself, did your own preconceptions influence which predictors should be relevant, and which parts of the population should be representative? It will be important to reflect on any personal biases that may have affected the input/output.
- Can the sampling process distort the data? Evaluate whether the method by which you interview people influenced their responses; or whether the questions themselves are suggestive.
If profiling reveals that your AI is not “fair” by the established metrics, there are three points at which you can mitigate the existing bias:
- On the training data
- In the model
- On predicted labels
We recommend that you conduct mitigation procedures as early as possible in the processing chain. We also advise that you test a variety of bias mitigation algorithms, since the effectiveness of an algorithm depends on data characteristics. Bias mitigation algorithms further differ by:
- The types of AI to which they apply; most of the algorithms proposed in the AI Fairness 360 open source toolkit are for a binary classifier (i.e., an AI that makes two-valued prediction, such as “yes/no”)
- The fairness metric(s) they support
- Whether the algorithm needs you to “tweak” input data (a real-life scenario might prevent you from doing this)
- How transparently the algorithm works, i.e., how explainable the results are after applying mitigation
5. Ensure human oversight
AI models are increasingly deployed to augment and replace human decision making. That is both their virtue, and their shortcoming. Autonomous vehicles, for example, may need to make life-and-death decisions without human supervision, based on human ethical values. Autonomous vehicle manufacturers risk losing control over their business if they are not able to evaluate algorithmic decisions to understand how the decisions are made and influenced.
Humans, therefore, must be involved at every step of the AI development process. This will help ensure that the AI system does not undermine human autonomy or cause other adverse effects. It will also be important for detecting bias and taking corrective action to eliminate it.
6. Ensure transparency
Human oversight alone is not enough. For AI to be considered responsible, a basic level of transparency must exist with respect to the development of the AI (including input factors such as technical processes and related human decisions); the AI’s decision-making process and decisions (output); and the AI itself and how it behaves. In essence, transparency involves traceability, communication and explainability.
Traceability involves documenting all training and test data sets, the processes used to train a machine learning AI and the algorithms used. This should include the input data for the decision and a log of relevant processing activities. Traceability can help to identify causes for erroneous AI decisions and identify corrective action. It will also be useful in any audit of the AI’s decision making.
Communication means first that AI systems identify themselves as such, and do not pretend to be humans. If the user has a right to interact with a human instead, the AI should communicate this clearly. It should also communicate openly its capabilities and limitations, the existence of any real or perceived issues (such as bias), and how it reaches its decisions.
Explainability is the most debated and least understood transparency component. However, given that international legislation will increasingly regulate AI and mandate transparency on companies worldwide, this deserves to be addressed (see sidebar: Legal and regulatory challenges).
At its most basic, “explainability” refers to the ability to show how an AI arrives at a particular decision. “Explainable AI” is AI with outputs that are sufficiently understandable to humans so that the AI’s decisions and impacts are accepted without question. Depending on the business context, privacy, security, algorithmic transparency and digital ethics may demand different levels of requirements for explainability. For example:
- AI that makes decisions about people, such as rejecting a loan application, may require explainability. By law, providers of algorithms must give the applicant a reason for the rejection.
- AI that makes decisions in a closed loop with important consequences, such as autonomous driving, also has a high need for explainability due to ethical and (possibly) legal reasons.
Of course, there are instances when AI algorithms should not be fully transparent (a company losing its competitive advantage by revealing proprietary secrets, or when personal data is involved), and others where transparency is not even possible (“black box” algorithms). The degree to which explainability is needed will depend on the context and on the severity of the consequences if that output is erroneous or otherwise inaccurate.
Explaining an AI’s decision does not necessarily mean a step-by-step traceback of the decision process. You also need to consider the target audience for the explanation (different stakeholder groups require different explanations), and determine what to explain, how and to whom.
Conclusion
We’ve reached an inflection point where companies that understand how to apply, deploy, embed and manage AI at scale are positioned to far outperform those that don’t (see Figure 3).
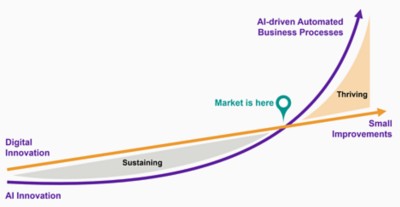
The value that AI can bring will not be fully realized while distrust and fear persists among some businesses and consumers of AI-based recommendations, insights and decisions. It is essential, therefore, that organizations developing AI make every effort to establish a responsible AI framework from the start. Once the framework is in place, an independent ombudsman body could be established within the organization to oversee compliance with the framework, and to handle contingencies and mitigation procedures, should the need arise. When AI outcomes are demonstrably sound — and therefore trusted as secure and safe by developers, users and regulators alike — there is no limit to how AI can be applied.
Next steps
DXC offers customers a variety of consultative services around AI:
- AI moonshots, advisory and implementation
- Responsible AI and AI ethics
- AI roadmap and strategy
- Business assessment about the impact of AI and monetizing advanced analytics
- Industrializing AI to achieve scale and trust in business applications
We engage clients wherever they are in their AI journey and offer a vendor-agnostic service. DXC partners with all major technology vendors in the AI space and can thus provide objective advice about how to use AI for growth, while observing best practices for responsible AI.
As a first step, refer to the checklist provided below to get you started on your journey to a responsible AI framework. You also can contact the DXC AI Advisory team to explore how DXC can help you on that journey.
I. Set the right goals
- Determine whether you have an existing system in place for managing ethics. If no system is in place, define unambiguous compliance and ethical objectives.
- Define clear objectives for what machine learning should learn and what AI should do.
- Define how you will measure your objectives in a quantifiable way.
II. Collect and prepare the data
- Understand various types of bias, the metrics for detecting them, which algorithm to use for what purpose and their potential side effects.
- Carefully evaluate whether training data is representative of the population and free from existing prejudice.
- Choose the right data fields to be considered for your AI.
- If necessary, apply bias mitigation methods on the training data.
- Ensure traceability of data collection and transformation activities. For example, ensure that for any release of an AI, you can document which training and test data was used, how the data was tested for bias, which bias mitigation techniques (if any) were applied and which fields were selected for training.
III. Profile the AI and assess risks
- Build forensic tools and profile the AI based on measurable (quantifiable) objectives.
- Evaluate outcomes of the profiling.
- Ensure traceability of risk assessment and mitigation practices. Document your findings.
IV. Mitigate bias
- If necessary, apply bias mitigation methods:
- Apply bias mitigation on the training data and re-train the algorithm(s).
- Influence the learning process to adjust to data bias.
- Re-weight output / recommendations, or apply bias mitigation methods directly on the output, when this is the appropriate method.
- Ensure traceability of bias assessment and mitigation activities. Document your actions and make them traceable to an AI release.
V. Operate the AI
- Conduct profiling and risk assessment activities on an ongoing basis. Monitor for drift if the algorithm is learning on an ongoing basis (see also: How to future-proof machine learning operations during major market shifts).
- If drift is detected, adjust bias mitigation.
- Update the traceability documentation (see also: Executive Data Series: AI for growth).
About the author
Kal Kanev is the director of the Global AI Practice at DXC. For over 11 years he has helped DXC customers with their AI journeys, being a Strategic Advisor for the C-suite, and directing AI teams in successfully embedding AI. Kal's experience includes helping design computer-assisted surgical instruments, to launching enterprise AI practices, enabling him to keep diverse groups focused on business outcomes. He leads customers to transform their value chain and elevate the customer experience when it requires complex AI and technology solutions. Connect with Kal on LinkedIn.